
Over the coming weeks, we will be releasing articles, videos, etc. exploring some of the new features of v25. One of the first requests we got was to take a look a new HF SQL feature that PC SOFT is calling Spare Server
Somethings one of the challenges with the new features is finding information about them in the online help system, so here is the link for you.
So what is a Spare Server and how is it different from Replication? This happens to be a topic I am familiar with and used at a former client site with both SQL Server and PostgreSQL backends, that had over 600 users.
Let’s talk about traditional Replication is first. Replication is generally used when you have an application user base that spans multiple geographic regions or is so large that one server can not handle the load of all the users. Two, or more, database servers are created with the same copy of the data, with a portion of users connecting to each server. Two-way replication is then implemented to keep the copies in sync. For example. A record gets created on Server 1, replication then creates the same record on Server 2. As you can imagine with two-way replication, things can get very complex when dealing with conflicts, etc. For example, a user on Server 1 change a Customer record, meanwhile, another user on Server 2 also makes changes to the same Customer record, before the changes from Server 1 made it to Server 2. Autoincrementing ID’s are also a challenge with two-way replication and require them to either be GUIDs or 8-byte integers. Bottom line 2 way replication requires constant management and programming considerations.
Spare Server or one-way replication as it’s referred to by most backend databases, on the other hand, is much easier to implement. You still have 2 or more servers and copies of the database, however, the extra servers are Read Only. Since you don’t have to worry about update conflicts, etc. there aren’t any programming concerns and no need for GUIDs or 8-byte integers. When changes are made to record on Server 1, those changes are also applied to Server 2. Think of it as a constant and nearly instant backup. In fact, the traditional use case for this type of replication is as a Hot Standby Server or as PC SOFT calls it a Spare Server. Without a Spare Server, if your database server has a catastrophic failure, the general recovery procedure is something like this:
- Build a new server
- Restore your previous backup (generally last nights)
- Recreate all the lost transactions since the last backup
This can lead to hours to even days of downtime! If you have a Spare Server in place, then all you do is promote the Spare Server as the master server, and continue working. At most you may have lost a few transactions right as the server failed. As you can see this is a great solution for mission-critical applications.
Providing a Hot Standby Server was the original reason we implemented one-way replication at that 600 user site I mentioned previously. But once we got it up and running it wasn’t long before we discovered a great secondary use case for a Spare Server. We noticed several slowdowns throughout the day and discovered these were caused by manage reports being run for sales analysis etc. These reports were data-intensive and but a considerable load on the database server. But remember the Spare Server is a copy of the master server, it just happens to be read-only, which isn’t an issue for reports. At the most, the Spare Server might be a couple of minutes behind the master server, which again generally isn’t an issue for reports. So we modified all of our reports to run off of the Spare Server, and the performance boost we got was amazing. Not only did we make the transaction users happy because they no longer faced slow-downs while working, but management was happier as well since their reports also performed better because they were no longer competing with resources with the transactional users.
Enough talk! Let’s see it in action. BTW, this page of the online help explains no to setup replication including Spare Server
For this example, I am going to set up my local HFSQL server as the master server, and then I am going to add one of our AWS servers as a Spare Server.
Step one is to set up the subscriber server, which is our Spare Server. So I connect to our soon to be Spare server using HFSQL Control Center.

Then click on Configuring the Server

And chose Replication from the list of options

We are configuring our Spare Server, so we turn on the check for The server is slave or spare. Replication takes place over a separate port from the standard database communication, the default is 4996, but you can change this if needed. NOTE: Be sure you open up that port for incoming traffic on your firewall. Replication is password protected so go ahead and specify the password your prefer. Obviously, this should be a complex password. Each server gets a unique ID between 1 and 32000. That’s right unfortunately you can set up replication to 32,000 servers, but I think that should take care of most of our needs! I used 2 because I want to assign 1 to the Master. There is also a priority setting with 1 being the highest. This is mainly for conflict resolution which really doesn’t apply to a Spare Server, again I set this value to 2 and I will set the Master to 1.

Once you have done that and opened up the port on the firewall, the Spare Server is ready to go. On to the Master Server, which in this example I am using my local HFSQL server. So I connect to it using the HFSQL Control Center
Again we navigate to Configuring the Server->Replication, however this time, we are defining the Master server so we take that checkbox, and as mentioned above I assigned it the ID of 1, and priority of 1.
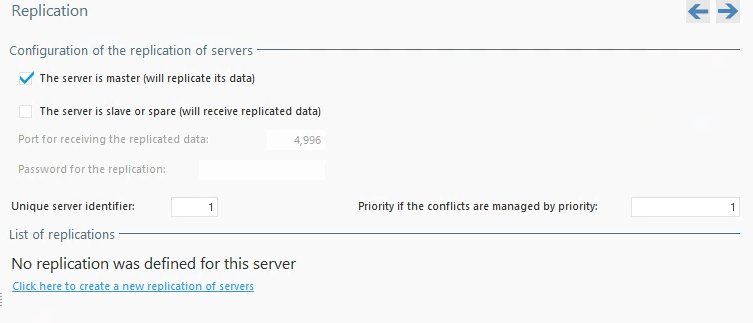
Notice in the above image, the link at the bottom titled, “Click here to create a new replication of servers”. All we have done so far is set up one server to be a standby, and the other to be a master. Now we need to set up the specific replication that we want to occur between the two servers by clicking that link, which launches a wizard. The first screen of the wizard is information, so we can click next.

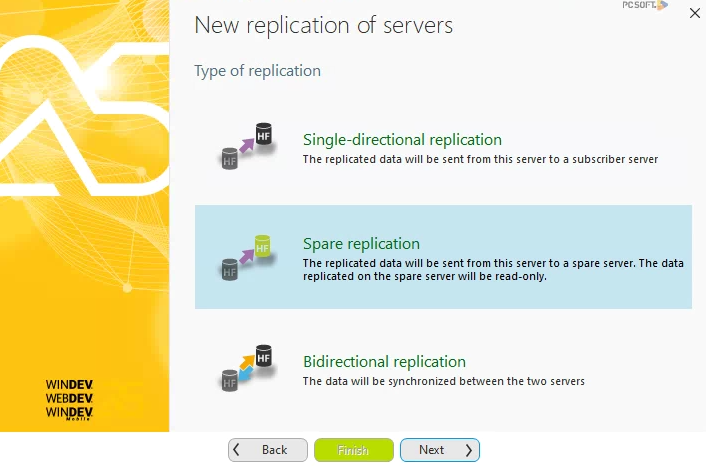
The next screen asks for the type of replication, which in this case will be Spare replication
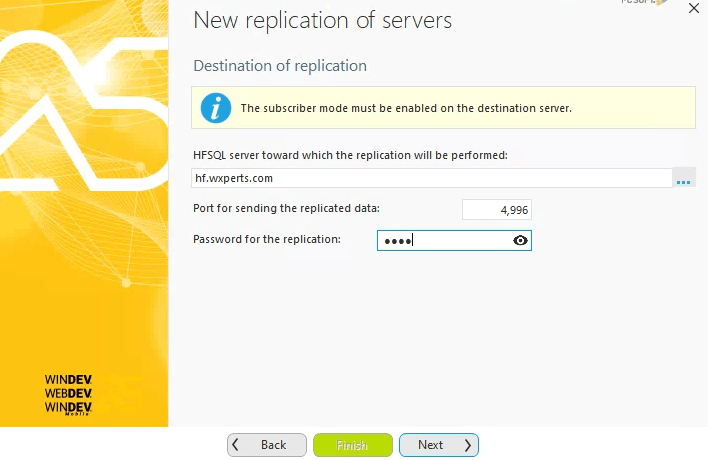
Next, we need to specify the address (IP) of the Spare server, as well as the port and password we set up earlier.
Next, you can either replicate the entire server, a specific database, or a selection of a database. You can even exclude some files of the database from the replication. For this example, I am going to just replication the wxDemov25 database. Note the checkbox “Perform an initial copy of the elements”, which will make a copy of the database on Spare Server, once replication has been set up, however with a large database, you might prefer to do the initial copy via backup media instead of over the internet.

Now we have the option to either perform the replication periodically or continuously. Depending on your needs, network, performance, etc. you might only want to replicate every hour for instance. For this example I choose Continous.
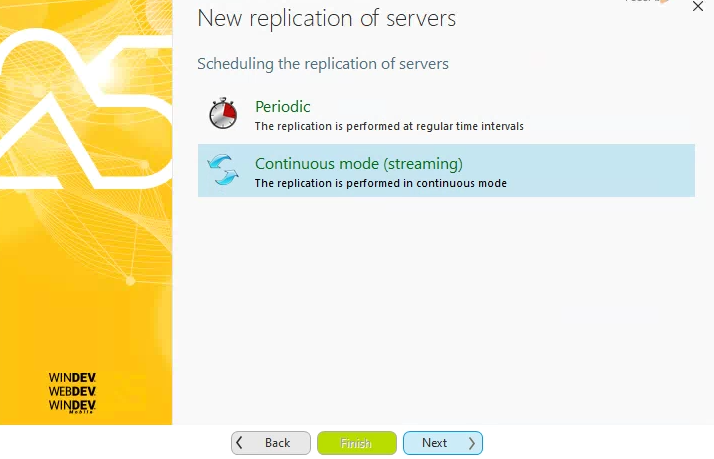
Finally, we reach the end of the configuration and after updating the description of the replication we can click the Finish button.
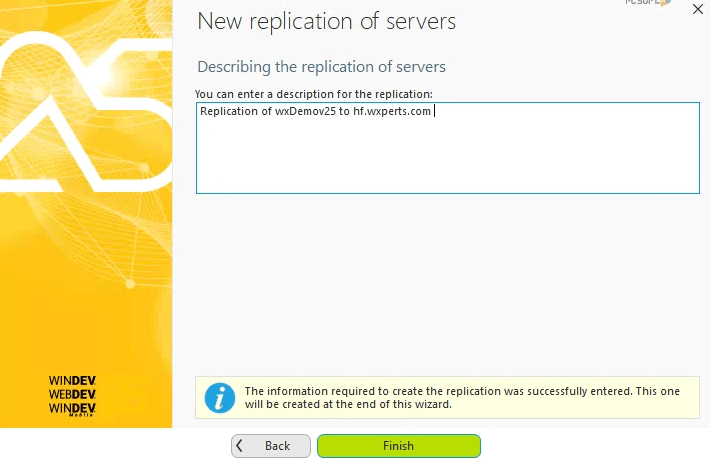
Because I used the option to perform the initial copy, it took 30 seconds or so to copy the data to our “Spare Server”

Once completed we can see the replication is configured on the server now.

If we return to the Spare Server we can see that it is connected to the Master Server as well.

We can also see that the database and data has made it to the Spare Server as well
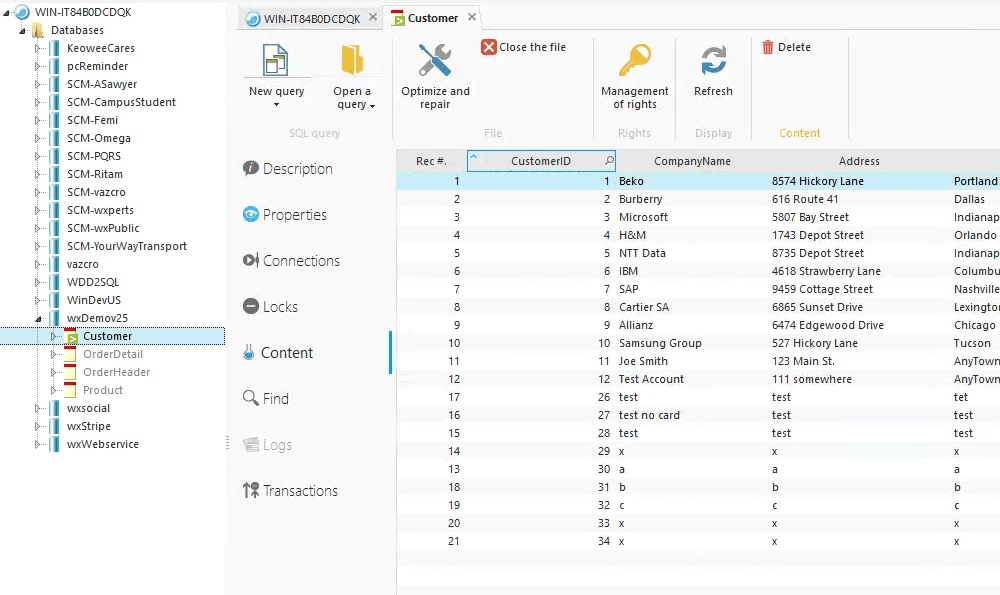
So now for a few quick tests using HFSQL Control Center, I opened an instance of the control center connected to each server. When I changed a record on the Master Server, and by the time I was able to switch over to the control center and do a refresh, the change was already on the Spare Server. Likewise, when adding a new record or deleting a record the change showed on the Spare Server almost instantly.
And when I tried to make a change to the database on the Spare Server, I got the following error, as I should.
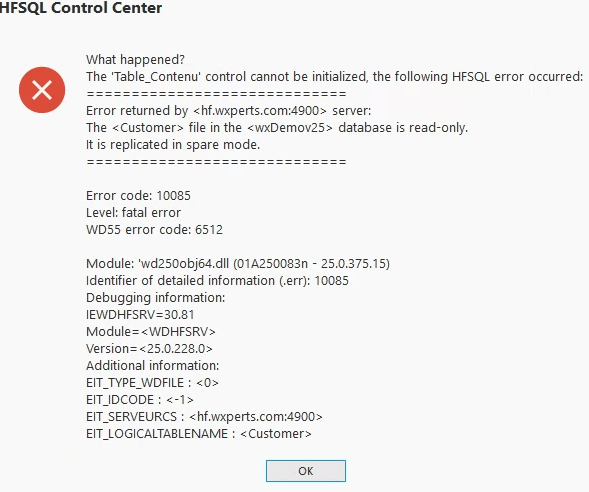
As far as your application goes there isn’t anything you need to change as all of this works at the HFSQL level. If you want to take it a step further and have your reports run against the Spare Server like I mentioned above that would be fairly easy to do with connection variables and HChangeConnection, which we already use with most of our applications and have shown before.
This just one of the many exciting new features that v25 brings us. Over the coming weeks, we will be doing articles, videos, example applications, etc. showing many more new features from v25, so be sure to join our Facebook group so you know when they are released.
